


コラム
2025/06/25

プログラミングについて 第111回目
『ハッシュ法 その2』
今回はハッシュ法と2分木を使ったプログラムの例を作ってみましょう。目的とする機能は、標準入力から単語を読み取り、単語の個数を出力するというものです。単語はスペースで区切られているとします。
さっそく作っていきましょう。まず基本型は次のとおりです。これは難しいところはありませんね。標準入力が終わりになるまで単語を読み込んで、標準出力にその単語を出力するだけの機能です。
#include <stdio.h>
main()
{
char word[81];
while(1){
scanf("%s",word);
if(feof(stdin))break;
printf("%s\n",word);
}
}
これに、2分木構造体へのポインタのハッシュテーブルを追加します。
struct node_strct{
char *word;
int total;
struct node_strct *left,*right;
};
#define MAX_TABLE 100
struct node_strct *table[MAX_TABLE];
このハッシュテーブル(table)の要素数は 100 としていますが、これは任意です。要素数が少ないと2分木ツリーが深くなる可能性があり、その逆では2分木ツリーは深くはなりませんが、ハッシュテーブルの無駄(未使用部分)が増える可能性がありますので、適当な値にします。
これを基本プログラムに追加し次のようにします。マクロの NEW と DELETE は以前にも説明してあるものです。このマクロは下のプログラムでは使いませんが、関数を作成していくうちに使用しますので予め追加しておきました。
#include <stdio.h>
#define NEW(type,element) (type *)malloc(sizeof(type)*(element))
#define DELETE(addr) free(addr)
struct node_strct{
char *word;
int total;
struct node_strct *left,*right;
};
#define MAX_TABLE 100
struct node_strct *table[MAX_TABLE];
main()
{
char word[81];
int i,j;
for(i=0;i<MAX_TABLE;i++)table[i]=NULL; /* テーブルの初期化 */
while(1){
scanf("%s",word);
if(feof(stdin))break;
add_word(word); /* 単語を追加 */
}
}
最初にハッシュテーブルの要素すべてを NULL にしておきます。
次が問題の関数 add_word です。
add_word(word)
char *word;
{
unsigned char *s;
int v;
/* 文字列の値の合計を求める */
v=0;
s=(unsigned char *)word;
while(*s)v+= *s++;
v%=MAX_TABLE; /* テーブルの要素数で剰余を求める */
/* テーブルの要素が空(ヌル)の
ときには2分木のノードを作成し、
そのポインタを代入。空でないときに
は、テーブルの要素が示す2分木のツ
リーにノードを追加します。 */
if(!table[v])table[v]=new_node(word);
else add_node(table[v],word);
}
関数 new_node は struct node_strct 構造体へのポインタを返す関数とするので、プロトタイプの宣言をしておかなければなりません。関数 add_word のハッシュ値の生成の方法は前回の説明のときと同じ方法としています。この方法以外にも、もっとばらつく方法があると思いますので試してみて下さい。
次は関数 new_node と add_node です。
関数 new_node はそれほど難しいものではありません。動的にメモリーを確保して必要な設定をし、そのアドレスを関数値として返すことを行ないます。
struct node_strct *new_node(word)
char *word;
{
struct node_strct *t;
t=NEW(struct node_strct,1);
t->word=NEW(char,strlen(word)+1);
strcpy(t->word,word);
t->total=1;
t->left =NULL;
t->right=NULL;
return t;
}
関数 add_node は再帰的に2分木にノードを追加します。同じ単語があったときには、
単語の総数(total メンバー)を1つ増やします。
add_node(tree,word)
struct node_strct *tree;
char *word;
{
int i;
i=strcmp(word,tree->word); /* 文字列を比較 */
if(i==0){ /* 同じときには総数を1つ増やす */
tree->total++;
}
else if(i<0){ /* 追加しようとする単語の方が小さいと
き、ノードの左がなければ、そこにノ
ードを新しく作って、そのポインタを
入れます。左があるときには再び左の
ノードを引数として add_node を呼び
出します */
if(tree->left)add_node(tree->left,word);
else tree->left=new_node(word);
}
else{ /* 追加しようとする単語の方が大きいと
きも、小さいときと同様に右側のノー
ドに対して操作します */
if(tree->right)add_node(tree->right,word);
else tree->right=new_node(word);
}
}
ここで一度これまでのプログラムの全体を載せておきます。
#include <stdio.h>
#define NEW(type,element) (type *)malloc(sizeof(type)*(element))
#define DELETE(addr) free(addr)
struct node_strct{
char *word;
int total;
struct node_strct *left,*right;
};
#define MAX_TABLE 100
struct node_strct *table[MAX_TABLE];
struct node_strct *new_node();
main()
{
char word[81];
int i,j;
for(i=0;i<MAX_TABLE;i++)table[i]=NULL;
while(1){
scanf("%s",word);
if(feof(stdin))break;
add_word(word);
}
}
add_word(word)
char *word;
{
unsigned char *s;
int v;
v=0;
s=(unsigned char *)word;
while(*s)v+= *s++;
v%=MAX_TABLE;
if(!table[v])table[v]=new_node(word);
else add_node(table[v],word);
}
struct node_strct *new_node(word)
char *word;
{
struct node_strct *t;
t=NEW(struct node_strct,1);
t->word=NEW(char,strlen(word)+1);
strcpy(t->word,word);
t->total=1;
t->left =NULL;
t->right=NULL;
return t;
}
add_node(tree,word)
struct node_strct *tree;
char *word;
{
int i;
i=strcmp(word,tree->word);
if(i==0){
tree->total++;
}
else if(i<0){
if(tree->left)add_node(tree->left,word);
else tree->left=new_node(word);
}
else{
if(tree->right)add_node(tree->right,word);
else tree->right=new_node(word);
}
}
ここまででハッシュテーブルと2分木の構造に単語とその総数を入れる機能が付きましたが、まだその結果を表示するようにはなっていません。
内容が分かりやすいような表示を行ないましょう。表示方法は各ハッシュテーブルの要素が示す2分木の構造を段下げを行なって分かりやすくすることにします。メイン関数の最後(単語を登録するループの後)に次のループを追加します。
for(i=0;i<MAX_TABLE;i++){
if(table[i]){
printf("----- %d -----\n",i);
display(table[i],0);
}
}
このループ内の関数 display の第1引数は2分木へのポインタ、第2引数は段下げの量です。この関数 display は、
display(tree,depth)
struct node_strct *tree;
int depth;
{
int i;
/* 左があるときには左の表示をする */
if(tree->left)display(tree->left,depth+2);
/* 段下げの量だけスペースを表示し、
総数と単語を表示 */
for(i=0;i<depth;i++)putchar(' ');
printf("%5d %s\n",tree->total,tree->word);
/* 右があるときには右の表示をする */
if(tree->right)display(tree->right,depth+2);
}
この関数も再帰呼び出しで行なっていますが、じっと見ていると理解できると思います。
それではこの関数を実行してみましょう。扱うデータは次のものとし、いま test.datというファイルに入っているとします。プログラム名は a.exe とします。
z
zz
zzz
zzzz
zzzzz
zzzzzz
zzzzzzz
zzzzzzzz
zzzzzzzzz
zzzzzzzzzz
zzzzzzzzzzz
zzzzzzzzzzzz
zzzzzzzzzzzzz
zzzzzzzzzzzzzz
zzzzzzzzzzzzzzz
DOSでは、
type | a.exe
UNIXでは、
cat | a.exe
として下さい。実行結果はちょっと長いのですが次のようになりました。
----- 4 -----
1 zzzzz
----- 8 -----
1 zzzzzzzzzz
----- 12 -----
1 zzzzzzzzzzzzzzz
----- 21 -----
1 z
----- 25 -----
1 zzzzzz
----- 29 -----
1 zzzzzzzzzzz
----- 42 -----
1 zz
----- 46 -----
1 zzzzzzz
----- 50 -----
1 zzzzzzzzzzzz
----- 63 -----
1 zzz
----- 67 -----
1 zzzzzzzz
----- 71 -----
1 zzzzzzzzzzzzz
----- 84 -----
1 zzzz
----- 88 -----
1 zzzzzzzzz
----- 92 -----
1 zzzzzzzzzzzzzz
この結果ではハッシュ関数が適当だったのか、各2分木の要素は1つだけになりました。
ここで、試しにハッシュテーブルの要素数を 10 にして実行してみると、
----- 0 -----
1 zzzzz
1 zzzzzzzzzz
1 zzzzzzzzzzzzzzz
----- 2 -----
1 z
1 zzzzzz
1 zzzzzzzzzzz
----- 4 -----
1 zz
1 zzzzzzz
1 zzzzzzzzzzzz
----- 6 -----
1 zzz
1 zzzzzzzz
1 zzzzzzzzzzzzz
----- 8 -----
1 zzzz
1 zzzzzzzzz
1 zzzzzzzzzzzzzz
となり、同一のハッシュ値になる文字列は2分木の構造になっています。どうしても元のデータが文字列としては小さい順で並んでいるので出来上がった各2分木は理想的なものにはなっていません。
次に試しに、関数 add_word を次のようにして実験してみます。
add_word(word)
char *word;
{
unsigned char *s;
int v;
/*コメントにする。
v=0;
s=(unsigned char *)word;
while(*s)v+= *s++;
v%=MAX_TABLE;
*/
v=0; /* 追加 */
if(!table[v])table[v]=new_node(word);
else add_node(table[v],word);
}
この変更は、ハッシュ値が常に 0 になるようにするものです。これを実行してみると、
----- 0 -----
1 z
1 zz
1 zzz
1 zzzz
1 zzzzz
1 zzzzzz
1 zzzzzzz
1 zzzzzzzz
1 zzzzzzzzz
1 zzzzzzzzzz
1 zzzzzzzzzzz
1 zzzzzzzzzzzz
1 zzzzzzzzzzzzz
1 zzzzzzzzzzzzzz
1 zzzzzzzzzzzzzzz
となり、2分木としては最悪の状態になってしまいました。確かに、ハッシュ値が 0 になる変更を行なう前の状態でも、それぞれの2分木は最悪の状態ですが、深さはそれ程深くはなっていません。
再びハッシュテーブルの要素数を 100 とし、実験してみました。テストに使ったデータは単語数が10万個程度で、その半分はソートしてあるものです。
私のパソコンでは、ハッシュ値が常に 0 になるようにしたものでは8秒、本来のものでは1秒でした。おおざっぱな比較ですがハッシュ法の利点が分かるかと思います。
最後にこれまでの全文です。
#include <stdio.h>
#define NEW(type,element) (type *)malloc(sizeof(type)*(element))
#define DELETE(addr) free(addr)
struct node_strct{
char *word;
int total;
struct node_strct *left,*right;
};
#define MAX_TABLE 100
struct node_strct *table[MAX_TABLE];
struct node_strct *new_node();
main()
{
char word[81];
int i,j;
for(i=0;i<MAX_TABLE;i++)table[i]=NULL;
while(1){
scanf("%s",word);
if(feof(stdin))break;
add_word(word);
}
for(i=0;i<MAX_TABLE;i++){
if(table[i]){
printf("----- %d -----\n",i);
display(table[i],0);
}
}
}
add_word(word)
char *word;
{
unsigned char *s;
int v;
v=0;
s=(unsigned char *)word;
while(*s)v+= *s++;
v%=MAX_TABLE;
if(!table[v])table[v]=new_node(word);
else add_node(table[v],word);
}
struct node_strct *new_node(word)
char *word;
{
struct node_strct *t;
t=NEW(struct node_strct,1);
t->word=NEW(char,strlen(word)+1);
strcpy(t->word,word);
t->total=1;
t->left =NULL;
t->right=NULL;
return t;
}
add_node(tree,word)
struct node_strct *tree;
char *word;
{
int i;
i=strcmp(word,tree->word);
if(i==0){
tree->total++;
}
else if(i<0){
if(tree->left)add_node(tree->left,word);
else tree->left=new_node(word);
}
else{
if(tree->right)add_node(tree->right,word);
else tree->right=new_node(word);
}
}
display(tree,depth)
struct node_strct *tree;
int depth;
{
int i;
if(tree->left)display(tree->left,depth+2);
for(i=0;i<depth;i++)putchar(' ');
printf("%5d %s\n",tree->total,tree->word);
if(tree->right)display(tree->right,depth+2);
}
次回は結果の表示を文字の小さい順に表示するように改修する予定です。
それではまた次回。
第111回 プログラミングについて『ハッシュ法 その2』
プログラミングについて 第111回目
『ハッシュ法 その2』
今回はハッシュ法と2分木を使ったプログラムの例を作ってみましょう。目的とする機能は、標準入力から単語を読み取り、単語の個数を出力するというものです。単語はスペースで区切られているとします。
さっそく作っていきましょう。まず基本型は次のとおりです。これは難しいところはありませんね。標準入力が終わりになるまで単語を読み込んで、標準出力にその単語を出力するだけの機能です。
#include <stdio.h>
main()
{
char word[81];
while(1){
scanf("%s",word);
if(feof(stdin))break;
printf("%s\n",word);
}
}
これに、2分木構造体へのポインタのハッシュテーブルを追加します。
struct node_strct{
char *word;
int total;
struct node_strct *left,*right;
};
#define MAX_TABLE 100
struct node_strct *table[MAX_TABLE];
このハッシュテーブル(table)の要素数は 100 としていますが、これは任意です。要素数が少ないと2分木ツリーが深くなる可能性があり、その逆では2分木ツリーは深くはなりませんが、ハッシュテーブルの無駄(未使用部分)が増える可能性がありますので、適当な値にします。
これを基本プログラムに追加し次のようにします。マクロの NEW と DELETE は以前にも説明してあるものです。このマクロは下のプログラムでは使いませんが、関数を作成していくうちに使用しますので予め追加しておきました。
#include <stdio.h>
#define NEW(type,element) (type *)malloc(sizeof(type)*(element))
#define DELETE(addr) free(addr)
struct node_strct{
char *word;
int total;
struct node_strct *left,*right;
};
#define MAX_TABLE 100
struct node_strct *table[MAX_TABLE];
main()
{
char word[81];
int i,j;
for(i=0;i<MAX_TABLE;i++)table[i]=NULL; /* テーブルの初期化 */
while(1){
scanf("%s",word);
if(feof(stdin))break;
add_word(word); /* 単語を追加 */
}
}
最初にハッシュテーブルの要素すべてを NULL にしておきます。
次が問題の関数 add_word です。
add_word(word)
char *word;
{
unsigned char *s;
int v;
/* 文字列の値の合計を求める */
v=0;
s=(unsigned char *)word;
while(*s)v+= *s++;
v%=MAX_TABLE; /* テーブルの要素数で剰余を求める */
/* テーブルの要素が空(ヌル)の
ときには2分木のノードを作成し、
そのポインタを代入。空でないときに
は、テーブルの要素が示す2分木のツ
リーにノードを追加します。 */
if(!table[v])table[v]=new_node(word);
else add_node(table[v],word);
}
関数 new_node は struct node_strct 構造体へのポインタを返す関数とするので、プロトタイプの宣言をしておかなければなりません。関数 add_word のハッシュ値の生成の方法は前回の説明のときと同じ方法としています。この方法以外にも、もっとばらつく方法があると思いますので試してみて下さい。
次は関数 new_node と add_node です。
関数 new_node はそれほど難しいものではありません。動的にメモリーを確保して必要な設定をし、そのアドレスを関数値として返すことを行ないます。
struct node_strct *new_node(word)
char *word;
{
struct node_strct *t;
t=NEW(struct node_strct,1);
t->word=NEW(char,strlen(word)+1);
strcpy(t->word,word);
t->total=1;
t->left =NULL;
t->right=NULL;
return t;
}
関数 add_node は再帰的に2分木にノードを追加します。同じ単語があったときには、
単語の総数(total メンバー)を1つ増やします。
add_node(tree,word)
struct node_strct *tree;
char *word;
{
int i;
i=strcmp(word,tree->word); /* 文字列を比較 */
if(i==0){ /* 同じときには総数を1つ増やす */
tree->total++;
}
else if(i<0){ /* 追加しようとする単語の方が小さいと
き、ノードの左がなければ、そこにノ
ードを新しく作って、そのポインタを
入れます。左があるときには再び左の
ノードを引数として add_node を呼び
出します */
if(tree->left)add_node(tree->left,word);
else tree->left=new_node(word);
}
else{ /* 追加しようとする単語の方が大きいと
きも、小さいときと同様に右側のノー
ドに対して操作します */
if(tree->right)add_node(tree->right,word);
else tree->right=new_node(word);
}
}
ここで一度これまでのプログラムの全体を載せておきます。
#include <stdio.h>
#define NEW(type,element) (type *)malloc(sizeof(type)*(element))
#define DELETE(addr) free(addr)
struct node_strct{
char *word;
int total;
struct node_strct *left,*right;
};
#define MAX_TABLE 100
struct node_strct *table[MAX_TABLE];
struct node_strct *new_node();
main()
{
char word[81];
int i,j;
for(i=0;i<MAX_TABLE;i++)table[i]=NULL;
while(1){
scanf("%s",word);
if(feof(stdin))break;
add_word(word);
}
}
add_word(word)
char *word;
{
unsigned char *s;
int v;
v=0;
s=(unsigned char *)word;
while(*s)v+= *s++;
v%=MAX_TABLE;
if(!table[v])table[v]=new_node(word);
else add_node(table[v],word);
}
struct node_strct *new_node(word)
char *word;
{
struct node_strct *t;
t=NEW(struct node_strct,1);
t->word=NEW(char,strlen(word)+1);
strcpy(t->word,word);
t->total=1;
t->left =NULL;
t->right=NULL;
return t;
}
add_node(tree,word)
struct node_strct *tree;
char *word;
{
int i;
i=strcmp(word,tree->word);
if(i==0){
tree->total++;
}
else if(i<0){
if(tree->left)add_node(tree->left,word);
else tree->left=new_node(word);
}
else{
if(tree->right)add_node(tree->right,word);
else tree->right=new_node(word);
}
}
ここまででハッシュテーブルと2分木の構造に単語とその総数を入れる機能が付きましたが、まだその結果を表示するようにはなっていません。
内容が分かりやすいような表示を行ないましょう。表示方法は各ハッシュテーブルの要素が示す2分木の構造を段下げを行なって分かりやすくすることにします。メイン関数の最後(単語を登録するループの後)に次のループを追加します。
for(i=0;i<MAX_TABLE;i++){
if(table[i]){
printf("----- %d -----\n",i);
display(table[i],0);
}
}
このループ内の関数 display の第1引数は2分木へのポインタ、第2引数は段下げの量です。この関数 display は、
display(tree,depth)
struct node_strct *tree;
int depth;
{
int i;
/* 左があるときには左の表示をする */
if(tree->left)display(tree->left,depth+2);
/* 段下げの量だけスペースを表示し、
総数と単語を表示 */
for(i=0;i<depth;i++)putchar(' ');
printf("%5d %s\n",tree->total,tree->word);
/* 右があるときには右の表示をする */
if(tree->right)display(tree->right,depth+2);
}
この関数も再帰呼び出しで行なっていますが、じっと見ていると理解できると思います。
それではこの関数を実行してみましょう。扱うデータは次のものとし、いま test.datというファイルに入っているとします。プログラム名は a.exe とします。
z
zz
zzz
zzzz
zzzzz
zzzzzz
zzzzzzz
zzzzzzzz
zzzzzzzzz
zzzzzzzzzz
zzzzzzzzzzz
zzzzzzzzzzzz
zzzzzzzzzzzzz
zzzzzzzzzzzzzz
zzzzzzzzzzzzzzz
DOSでは、
type | a.exe
UNIXでは、
cat | a.exe
として下さい。実行結果はちょっと長いのですが次のようになりました。
----- 4 -----
1 zzzzz
----- 8 -----
1 zzzzzzzzzz
----- 12 -----
1 zzzzzzzzzzzzzzz
----- 21 -----
1 z
----- 25 -----
1 zzzzzz
----- 29 -----
1 zzzzzzzzzzz
----- 42 -----
1 zz
----- 46 -----
1 zzzzzzz
----- 50 -----
1 zzzzzzzzzzzz
----- 63 -----
1 zzz
----- 67 -----
1 zzzzzzzz
----- 71 -----
1 zzzzzzzzzzzzz
----- 84 -----
1 zzzz
----- 88 -----
1 zzzzzzzzz
----- 92 -----
1 zzzzzzzzzzzzzz
この結果ではハッシュ関数が適当だったのか、各2分木の要素は1つだけになりました。
ここで、試しにハッシュテーブルの要素数を 10 にして実行してみると、
----- 0 -----
1 zzzzz
1 zzzzzzzzzz
1 zzzzzzzzzzzzzzz
----- 2 -----
1 z
1 zzzzzz
1 zzzzzzzzzzz
----- 4 -----
1 zz
1 zzzzzzz
1 zzzzzzzzzzzz
----- 6 -----
1 zzz
1 zzzzzzzz
1 zzzzzzzzzzzzz
----- 8 -----
1 zzzz
1 zzzzzzzzz
1 zzzzzzzzzzzzzz
となり、同一のハッシュ値になる文字列は2分木の構造になっています。どうしても元のデータが文字列としては小さい順で並んでいるので出来上がった各2分木は理想的なものにはなっていません。
次に試しに、関数 add_word を次のようにして実験してみます。
add_word(word)
char *word;
{
unsigned char *s;
int v;
/*コメントにする。
v=0;
s=(unsigned char *)word;
while(*s)v+= *s++;
v%=MAX_TABLE;
*/
v=0; /* 追加 */
if(!table[v])table[v]=new_node(word);
else add_node(table[v],word);
}
この変更は、ハッシュ値が常に 0 になるようにするものです。これを実行してみると、
----- 0 -----
1 z
1 zz
1 zzz
1 zzzz
1 zzzzz
1 zzzzzz
1 zzzzzzz
1 zzzzzzzz
1 zzzzzzzzz
1 zzzzzzzzzz
1 zzzzzzzzzzz
1 zzzzzzzzzzzz
1 zzzzzzzzzzzzz
1 zzzzzzzzzzzzzz
1 zzzzzzzzzzzzzzz
となり、2分木としては最悪の状態になってしまいました。確かに、ハッシュ値が 0 になる変更を行なう前の状態でも、それぞれの2分木は最悪の状態ですが、深さはそれ程深くはなっていません。
再びハッシュテーブルの要素数を 100 とし、実験してみました。テストに使ったデータは単語数が10万個程度で、その半分はソートしてあるものです。
私のパソコンでは、ハッシュ値が常に 0 になるようにしたものでは8秒、本来のものでは1秒でした。おおざっぱな比較ですがハッシュ法の利点が分かるかと思います。
最後にこれまでの全文です。
#include <stdio.h>
#define NEW(type,element) (type *)malloc(sizeof(type)*(element))
#define DELETE(addr) free(addr)
struct node_strct{
char *word;
int total;
struct node_strct *left,*right;
};
#define MAX_TABLE 100
struct node_strct *table[MAX_TABLE];
struct node_strct *new_node();
main()
{
char word[81];
int i,j;
for(i=0;i<MAX_TABLE;i++)table[i]=NULL;
while(1){
scanf("%s",word);
if(feof(stdin))break;
add_word(word);
}
for(i=0;i<MAX_TABLE;i++){
if(table[i]){
printf("----- %d -----\n",i);
display(table[i],0);
}
}
}
add_word(word)
char *word;
{
unsigned char *s;
int v;
v=0;
s=(unsigned char *)word;
while(*s)v+= *s++;
v%=MAX_TABLE;
if(!table[v])table[v]=new_node(word);
else add_node(table[v],word);
}
struct node_strct *new_node(word)
char *word;
{
struct node_strct *t;
t=NEW(struct node_strct,1);
t->word=NEW(char,strlen(word)+1);
strcpy(t->word,word);
t->total=1;
t->left =NULL;
t->right=NULL;
return t;
}
add_node(tree,word)
struct node_strct *tree;
char *word;
{
int i;
i=strcmp(word,tree->word);
if(i==0){
tree->total++;
}
else if(i<0){
if(tree->left)add_node(tree->left,word);
else tree->left=new_node(word);
}
else{
if(tree->right)add_node(tree->right,word);
else tree->right=new_node(word);
}
}
display(tree,depth)
struct node_strct *tree;
int depth;
{
int i;
if(tree->left)display(tree->left,depth+2);
for(i=0;i<depth;i++)putchar(' ');
printf("%5d %s\n",tree->total,tree->word);
if(tree->right)display(tree->right,depth+2);
}
次回は結果の表示を文字の小さい順に表示するように改修する予定です。
それではまた次回。

最近の投稿
-
名刺サイズ以下に収めた、WiFi内蔵の 工業用レーザーセンサー基板
 2026/07/09
2026/07/09 -
クラウド不要、端末側で完結するEdgeAI顔認証システム(Cortex-M7+Edge TPU)
 2026/07/09
2026/07/09 -
イメージがありません。ディスコン対応:MAX7000(CPLD)からCycloneⅣ(FPGA)へのリプレース(AHDL→VHDL変換)2026/07/09
-
イメージがありません。ディスコン対応:AHDL資産を活かしたAltera MAX3000のリプレース(AHDL→VHDL変換)2026/07/09
-
既存電話設備とIPネットワークをつなぐ、VoIP-PCMハイウェイ相互変換装置の開発
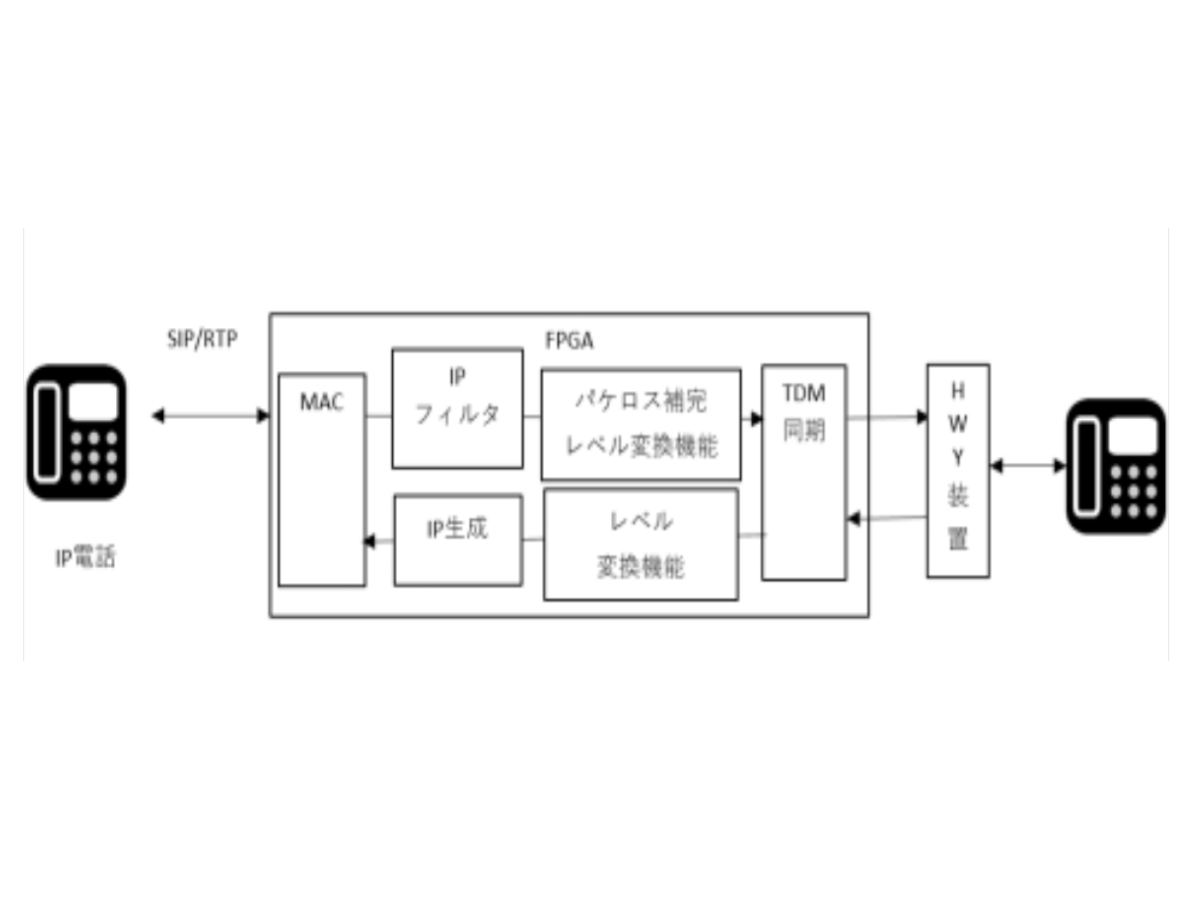 2026/07/09
2026/07/09

