


コラム
2025/05/28

プログラミングについて 第109回目
『ファイルを圧縮してみよう! その8』
~LZ法で圧縮したファイルを伸長する~
今回は前回までに作成したLZ法で圧縮するプログラムで作成したファイルを伸長するプログラムを作成しましょう。圧縮よりも伸長の方が簡単です。
グローバルな変数や定数は次のとおりです。もう説明の必要はありませんね。
#include <stdio.h>
#define IN_FNAME "x.x"
#define OUT_FNAME "y.y"
#define MAX_TEXT 256
#define MAX_BASE_TEXT (MAX_TEXT*10)
char base_text[MAX_BASE_TEXT];
char *text;
int ltext;
char ichar;
int ichar_remain;
FILE *ifp,*ofp;
この伸長プログラムでは前回に圧縮時間を改善したときと同じ手法で255文字前までの文字配列を処理します。
メイン関数は、
main()
{
ifp=fopen( IN_FNAME,"rb");
ofp=fopen(OUT_FNAME,"wb");
text=base_text;
ltext=0;
ichar_remain=0;
expand();
fclose(ifp);
fclose(ofp);
}
これももう説明の必要がないでしょう。
次に伸長する関数 expand() です。
expand()
{
while(1){
if(get_bit()==0){
output_char();
}
else{
if(output_same())break;
}
}
}
これも悲しいくらいに簡単です。1ビットを読み込みそれが0ならば次にあるものが文字で、1のときには前の文字と一致しているという情報です。
get_bit() 関数は、
get_bit()
{
int ret;
if(ichar_remain<=0){
ichar=fgetc(ifp);
ichar_remain=8;
}
if(ichar & 0x80)ret=1;
else ret=0;
ichar<<=1;
ichar_remain--;
return ret;
}
この関数も何度か出てきましたので説明は省略します。1文字出力する関数は次のとおりです。
output_char()
{
char c;
int i;
c=0;
for(i=0;i<=7;i++){
c<<=1;
c|=get_bit();
}
fputc(c,ofp);
add_char(c);
}
入力ファイルから8ビット読み込んで(1文字)それを出力した後、add_char 関数で255文字前までの文字配列にその文字を追加します。
前の文字と同じというデータの処理は、
output_same()
{
int prev,len;
char c;
int i;
prev=0;
for(i=0;i<=7;i++){
prev<<=1;
prev|=get_bit();
}
len=0;
for(i=0;i<=7;i++){
len<<=1;
len|=get_bit();
}
if(prev==0)return 1;
while(len-- >0){
c=text[ltext-prev];
fputc(c,ofp);
add_char(c);
}
return 0;
}
で、何文字前を示す1バイトと何文字かを示す1バイトを入力ファイルから読み込んだ後、その文字を順次出力し、再びその文字を255文字前までの文字配列に追加します。
最後に255前までの文字配列に1文字を追加する関数です。
add_char(c)
char c;
{
if(ltext>=MAX_TEXT){
text++;
ltext--;
}
text[ltext++]=c;
if(text+ltext>=base_text+MAX_BASE_TEXT){
memcpy(base_text,text,MAX_TEXT);
text=base_text;
}
}
これも前回説明しましたので説明は省略します。
これで伸長プログラムが完成です。あまりにも単純でがっかりしたと思います。
試しに前回まで対象にしていた1.3メガのファイルを圧縮後に伸長する時間は1秒で終了しました。
プログラムの全文は今回紹介したプログラムのリスト全部ですので省略します。
それではまた次回。
第109回 プログラミングについて『ファイルを圧縮してみよう! その8』
プログラミングについて 第109回目
『ファイルを圧縮してみよう! その8』
~LZ法で圧縮したファイルを伸長する~
今回は前回までに作成したLZ法で圧縮するプログラムで作成したファイルを伸長するプログラムを作成しましょう。圧縮よりも伸長の方が簡単です。
グローバルな変数や定数は次のとおりです。もう説明の必要はありませんね。
#include <stdio.h>
#define IN_FNAME "x.x"
#define OUT_FNAME "y.y"
#define MAX_TEXT 256
#define MAX_BASE_TEXT (MAX_TEXT*10)
char base_text[MAX_BASE_TEXT];
char *text;
int ltext;
char ichar;
int ichar_remain;
FILE *ifp,*ofp;
この伸長プログラムでは前回に圧縮時間を改善したときと同じ手法で255文字前までの文字配列を処理します。
メイン関数は、
main()
{
ifp=fopen( IN_FNAME,"rb");
ofp=fopen(OUT_FNAME,"wb");
text=base_text;
ltext=0;
ichar_remain=0;
expand();
fclose(ifp);
fclose(ofp);
}
これももう説明の必要がないでしょう。
次に伸長する関数 expand() です。
expand()
{
while(1){
if(get_bit()==0){
output_char();
}
else{
if(output_same())break;
}
}
}
これも悲しいくらいに簡単です。1ビットを読み込みそれが0ならば次にあるものが文字で、1のときには前の文字と一致しているという情報です。
get_bit() 関数は、
get_bit()
{
int ret;
if(ichar_remain<=0){
ichar=fgetc(ifp);
ichar_remain=8;
}
if(ichar & 0x80)ret=1;
else ret=0;
ichar<<=1;
ichar_remain--;
return ret;
}
この関数も何度か出てきましたので説明は省略します。1文字出力する関数は次のとおりです。
output_char()
{
char c;
int i;
c=0;
for(i=0;i<=7;i++){
c<<=1;
c|=get_bit();
}
fputc(c,ofp);
add_char(c);
}
入力ファイルから8ビット読み込んで(1文字)それを出力した後、add_char 関数で255文字前までの文字配列にその文字を追加します。
前の文字と同じというデータの処理は、
output_same()
{
int prev,len;
char c;
int i;
prev=0;
for(i=0;i<=7;i++){
prev<<=1;
prev|=get_bit();
}
len=0;
for(i=0;i<=7;i++){
len<<=1;
len|=get_bit();
}
if(prev==0)return 1;
while(len-- >0){
c=text[ltext-prev];
fputc(c,ofp);
add_char(c);
}
return 0;
}
で、何文字前を示す1バイトと何文字かを示す1バイトを入力ファイルから読み込んだ後、その文字を順次出力し、再びその文字を255文字前までの文字配列に追加します。
最後に255前までの文字配列に1文字を追加する関数です。
add_char(c)
char c;
{
if(ltext>=MAX_TEXT){
text++;
ltext--;
}
text[ltext++]=c;
if(text+ltext>=base_text+MAX_BASE_TEXT){
memcpy(base_text,text,MAX_TEXT);
text=base_text;
}
}
これも前回説明しましたので説明は省略します。
これで伸長プログラムが完成です。あまりにも単純でがっかりしたと思います。
試しに前回まで対象にしていた1.3メガのファイルを圧縮後に伸長する時間は1秒で終了しました。
プログラムの全文は今回紹介したプログラムのリスト全部ですので省略します。
それではまた次回。

最近の投稿
-
名刺サイズ以下に収めた、WiFi内蔵の 工業用レーザーセンサー基板
 2026/07/09
2026/07/09 -
クラウド不要、端末側で完結するEdgeAI顔認証システム(Cortex-M7+Edge TPU)
 2026/07/09
2026/07/09 -
イメージがありません。ディスコン対応:MAX7000(CPLD)からCycloneⅣ(FPGA)へのリプレース(AHDL→VHDL変換)2026/07/09
-
イメージがありません。ディスコン対応:AHDL資産を活かしたAltera MAX3000のリプレース(AHDL→VHDL変換)2026/07/09
-
既存電話設備とIPネットワークをつなぐ、VoIP-PCMハイウェイ相互変換装置の開発
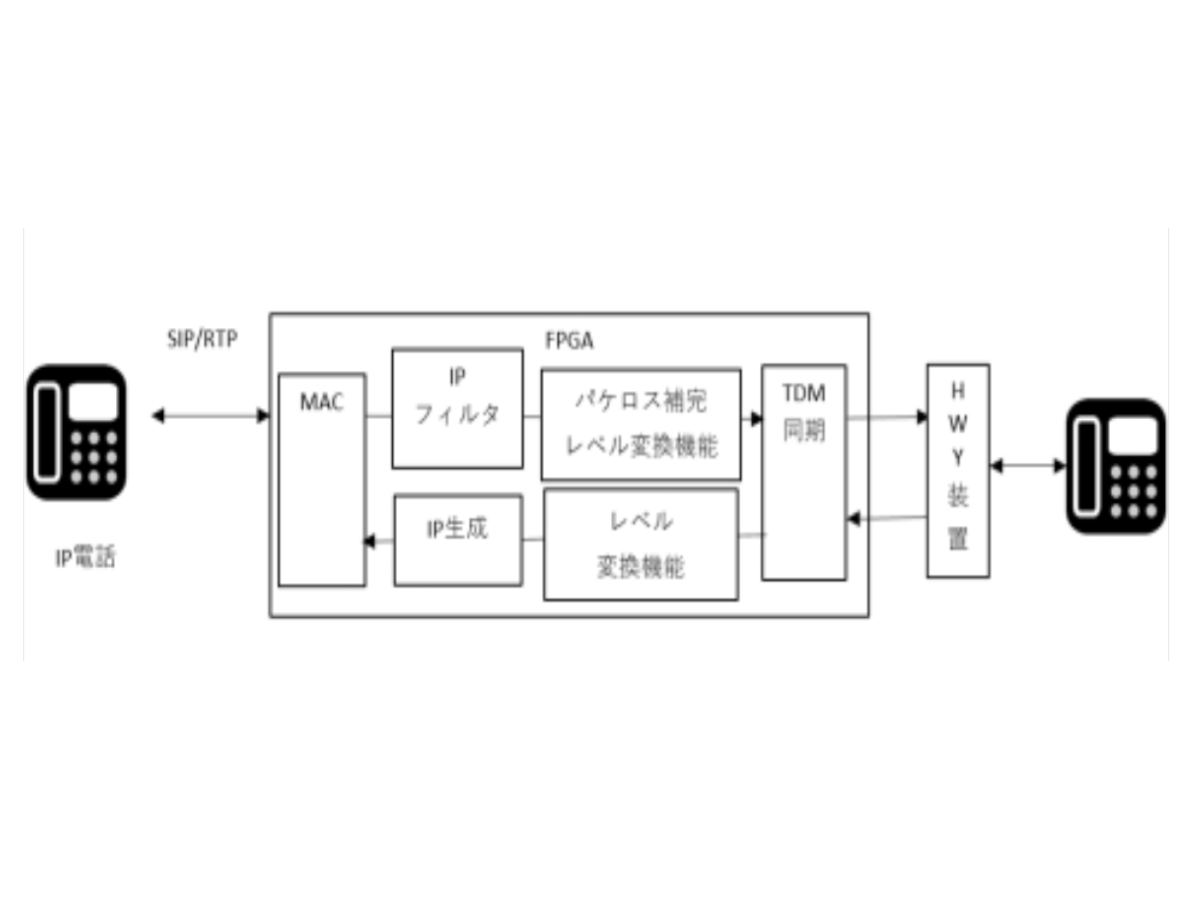 2026/07/09
2026/07/09

